Expert Databricks Consulting Services — Accelerate Analytics& Lakehouse Adoption
 Architecture Design
Architecture Design Azure & AWS Databricks Deployment
Azure & AWS Databricks Deployment Databricks Lakehouse Engineering
Databricks Lakehouse Engineering Workflows & Pipeline Automation
Workflows & Pipeline Automation Dashboard & BI Integration
Dashboard & BI Integration Databricks Migration Services
Databricks Migration Services




Partnered with Startups and Fortune 500





Recognised For Excellence in Databricks Consulting
Dotsquares is a recognised technology partner and preferred consultancy for Fortune 500 firms, scale-up enterprises, and data-led startups seeking to maximise the value of the Databricks platform. Our expertise spans Databricks architecture design, lakehouse engineering, ML and AI workload optimization, Databricks workflows automation, and cloud-native deployment across Azure, AWS, and GCP delivering the performance, reliability, and cost efficiency your data platform demands.
Our Databricks Consulting Services — From Architecture to Production
We design your architecture around your actual data volumes, workloads, and cost targets; covering medallion lakehouse structure, Unity Catalog governance, cluster topology, and network security configuration, so the platform is production-ready before a single pipeline runs.

We implement Databricks on AWS with proper integration into S3, Glue Catalog, Lake Formation, Redshift, and Kinesis, configuring VPC networking, cross-account access, IAM roles, and cost allocation tagging so your Databricks environment fits cleanly into your existing AWS setup.
We implement Databricks on AWS with proper integration into S3, Glue Catalog, Lake Formation, Redshift, and Kinesis configuring VPC networking, cross-account access, IAM roles, and cost allocation tagging so your Databricks environment fits cleanly into your existing AWS setup.
We design and implement your Delta Lake table structures, configure Z-ordering and data skipping for query performance, build Change Data Capture pipelines, and deploy Delta Live Tables, giving your analytics and ML teams clean, reliable data without the trade-offs of a traditional data lake.
We design and implement multi-task Workflows covering ingestion, transformation, quality validation, ML training, and model deployment with dependency management, retry logic, SLA alerting, and CI/CD integration built in from the start.
We implement Lakeflow connectors, configure managed ingestion from your SaaS applications and databases, and handle schema drift and evolution delivering clean, Delta Lake-ready datasets to downstream consumers without the overhead of managing traditional ETL infrastructure
We build custom integrations, automation scripts, and internal tooling using the Databricks REST API and SDKs embedding cluster management, job triggering, secrets handling, and Unity Catalog operations directly into your existing business applications and operational workflows.
We build end-to-end ML pipelines in Databricks setting up MLflow tracking, Feature Store pipelines, Model Serving endpoints, and MLOps CI/CD workflows so models move from experimentation into production reliably, with GPU clusters tuned for training performance.
We will configure the SQL warehouse optimized for BI workloads, build Databricks dashboard solutions for operations analytics, and integrate with Power BI, Tableau, Looker, and Sigma. Business users can keep using familiar tools while relying on the performance of Delta Lake.
We assess your existing workloads, translate legacy ETL and SQL code to Spark and Delta Live Tables, migrate historical data to Delta Lake format, and run performance benchmarking before anything touches production so the cutover is clean and the risk is managed.
What Databricks Does — And Why It Changes Everything for Data Teams
It is the Unified Data Intelligence Platform, combining data engineering, data warehousing, streaming analytics, machine learning, and AI on a single, lakehouse-native foundation. Here is a clear overview of the core platform capabilities our consultants work with every day:
| Capability | What It Enables | |
|---|---|---|
| Delta Lake | Open-source storage layer providing ACID transactions, schema enforcement, time travel, and Z-order indexing on data lake files is the foundation of the Databricks Lakehouse. | |
| Delta Live Tables | Declarative pipeline framework for building reliable data transformation pipelines with built-in data quality enforcement, automatic dependency management, and incremental processing. | |
| Databricks Lakeflow | Managed ingestion service that connects to 200+ SaaS and database sources, enabling low-latency, governed data delivery to Delta Lake without custom connector engineering. | |
| Workflows | Native orchestration engine for scheduling and managing multi-task data pipelines, ML training jobs, and notebook runs with dependency graphs, retry logic, and operational alerting. | |
| Unity Catalog | Unified governance layer for data and AI assets across all Databricks workspaces providing fine-grained access control, data lineage, audit logging, and column-level security. | |
| Databricks SQL | Serverless SQL warehouse for running high-performance analytical queries on Delta Lake tables with auto-scaling compute, query caching, and native integration with BI tools. | |
| Visual Dashboard | Native visualisation and dashboarding capability built directly on Databricks SQL enabling data teams to build and publish operational dashboards without leaving the platform. | |
| MLflow & Model Serving | Open-source ML lifecycle platform integrated natively with Databricks covering experiment tracking, model registry, feature store, and real-time model serving at production scale. | |
| Databricks API | Comprehensive REST API and CLI enabling programmatic control of every platform resource clusters, jobs, notebooks, secrets, Unity Catalog assets, and ML endpoints. |
Let’s Turn Your Data Into Opportunities!
Hire Certified Databricks Developers — On Demand
Businesses struggle to maximize tech investments in today's fast-changing environment. Our 20+ years of experience can help you get the most out of your technology. We offer flexible solutions that adapt to your evolving needs.


 Azure Data Factory
Azure Data FactoryStreamline your data workflows across Azure services effortlessly with Azure Data Factory. Optimize operations and gain insights faster than ever before.
Learn More
 Databricks
DatabricksDrive innovation with advanced analytics and AI using Databricks. Accelerate data-driven decisions and unlock new opportunities for growth and efficiency.
Learn More
 Snowflake
SnowflakeSupercharge your data storage and processing with Snowflake. Our solutions deliver lightning-fast insights that empower quick and informed decision-making.
Learn More
 Business Intelligence & Power BI
Business Intelligence & Power BIData engineering is the process of designing, building, and maintaining data infrastructure to support data-driven decision-making and business operations.
Learn MoreHire Big Data Engineers
Our data engineer specializes in advanced programs that encompas the following areas:

AWS data engineer
Specializing in Amazon Web Services, our team provides tailored solutions that ensure robust performance and scalability for your data needs.

Azure data engineer
Using Microsoft Azure, we excel in executing comprehensive data engineering projects, optimizing workflows, and enhancing integration capabilities.

GCP data engineer
With expertise in Google Cloud Platform, we provide efficient data management solutions that enhance your data analytics and storage capabilities.

DataOps engineer
Our DataOps specialists optimize data operation pipelines across various platforms, to ensure seamless data flow processes and maximize operational efficiency.
Why Enterprises Choose Dotsquares as Their Databricks Consulting Partner
With a team of over 1,000+ experts combined with their exclusive experience, we offer comprehensive data analytics engineering services to help businesses make informed, data-driven decisions.
Transform your enterprise data into actionable insights with Dotsquares, your trusted partner in data engineering.
Connect with Us!



What You Get When You Partner with Dotsquares

ISO 27001 Certified Security
We maintain the highest international standards for data protection with ISO 27001:2022 certification, ensuring your intellectual property and sensitive information remain 100% secure.

1000+ In-House Developers
Our team of 1,000+ in-house experts is recruited through a rigorous screening process, selecting only the top technical talent to ensure premium quality for every project.

24+ Years of Proven Excellence
With over 27,000+ successful projects delivered since 2002, we bring deep industry experience and a stable, reliable foundation to every partnership we build.

Trusted Global Technology Partners
We are proud Microsoft Gold, AWS, and Salesforce Consulting partners, ensuring your solutions are built using the latest enterprise-grade technologies.
Databricks Solutions We Have Built
Explore some of our development projects demonstrating our expertise in harnessing to create robust and scalable solutions.

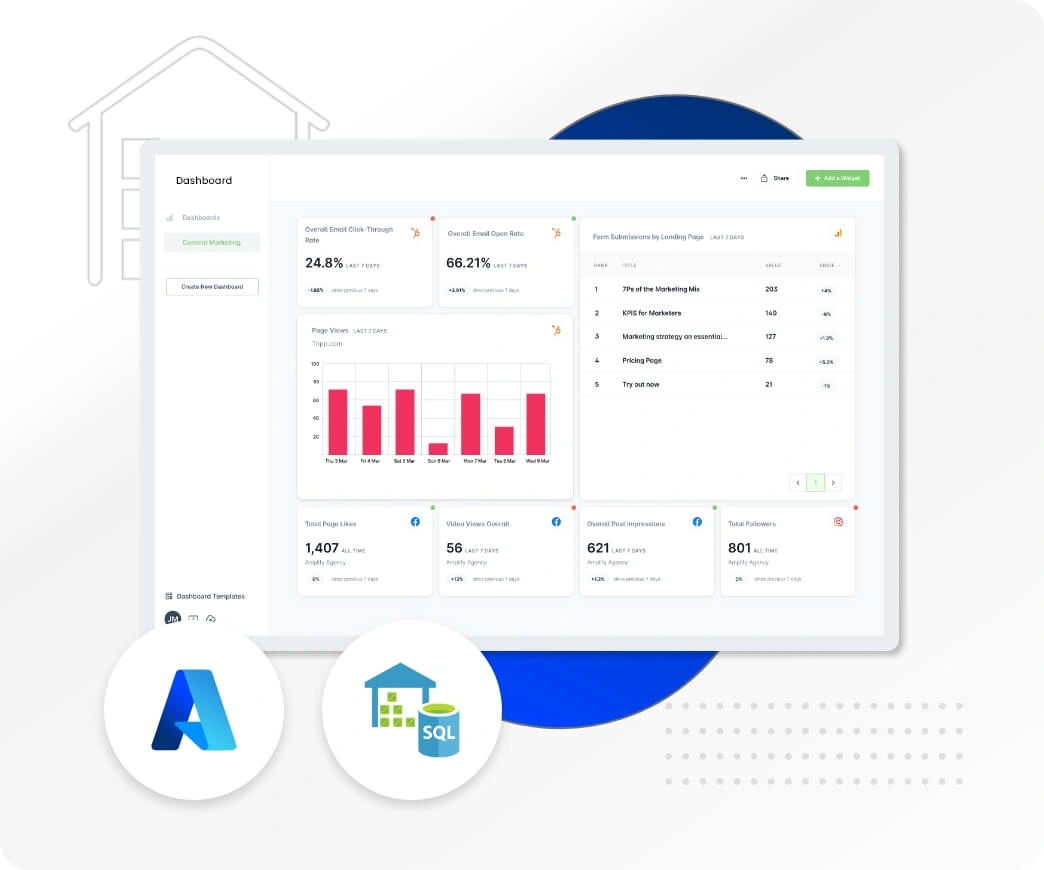
Data Engineering Solution
Ivy Enterprise
 Challenges
Challenges
Managing diverse sales data sources efficiently and selecting the right analytics tools were key challenges.
 Solution
Solution
To address these challenges, we automated data collection with Power BI, implemented effective data visualization, and used Azure Functions for real-time data extraction. Microsoft Azure Power BI provided robust analytics, enhancing decision-making across the client's restaurant enterprises.
- TECHNOLOGY Azure
- Region UK
Building Production-Ready
Infrastructure withScalable Pipelines
Unified Governance
Real-Time Processing
We design and implement end-to-end Databricks pipeline automation — from raw data ingestion through Databricks Lakeflow. Every pipeline is governed by Unity Catalog, monitored via Databricks Workflows alerting, and version-controlled through Azure DevOps or GitHub Actions.
- Databricks Autoloader and ingestion
- Delta Live Tables management
- Unity Catalog and lineage
- Databricks Workflows scheduling

We build the SQL and dashboard infrastructure that gives your business users self-service analytics on a governed, high-performance lakehouse. This includes SQL warehouse configuration for optimal BI query performance, and DirectQuery integration
- SQL warehouse auto-scaling
- Databricks Dashboard Creation
- Power BI integration
- Unity Catalog and data masking

Whether you are adopting Databricks for the first time or modernising an existing implementation, we help you design the lakehouse architecture that fits your actual requirements. We assess your current data sources, analytics workloads then design the Data environment to deliver maximum performance.
- Architecture assessment and design
- Multi-workspace Catalog strategy
- Migration planning
- Cost governance and optimisation

Tailored Technologies to Conquer Your Development Challenges
Our consulting practice integrates with your full technology stack — from cloud platforms and streaming systems to BI tools, ML frameworks, and enterprise data sources.


























































The Advantages of Working with Dotsquares
We craft solutions that transform your business. Here's what sets us apart:

Competitive Rates
Our rates are highly competitive, ensuring that you receive excellent value for your money. With us, you can be confident that you are getting the best possible rates without compromising on quality.

Quality
We take pride in delivering exceptional results. Our CMMI level 3 appraisal and membership in the Agile Alliance demonstrate our commitment to strong processes and quality control. This ensures you get a polished, high-quality product every single time.
In-House Expertise
Our 1,000+ designers, developers, and project managers are all directly employed by us and work in our own offices across the US, UK, India, and globally. This ensures seamless collaboration and control over your project.

Security & Confidentiality
Unlike many offshore companies, security is our top priority. Your data and intellectual property remain completely confidential, and all source code rights belong to you, always.

On-Time Delivery
We use cutting-edge project management tools and agile development practices to keep your project on track. This means you'll get high-quality products delivered exactly when you expect them.

Flexible Engagement Models
We understand that your needs can change. That's why we offer flexible engagement options. Choose the model that works best for you now, and switch seamlessly if your needs evolve. We're committed to building a long-term, reliable partnership with you.
Flexible Engagement Models for Every Project
At Dotsquares, we provide flexible options for accessing our developers' time, allowing you to choose the duration and frequency of their availability based on your specific requirements.

 Bucket hours
Bucket hoursWhen you buy bucket hours, you purchase a set number of hours upfront.
- Your purchased bucket hours remain valid for 6 months, during this time frame, you can utilize our services until your hours are exhausted or until the 6-month period expires.
- For example, if you invest in 40 bucket hours and use 10 hours within the first month, you will have a remaining 30 hours to utilize over the next 5 months.
- In this case, the developer will work for other projects simultaneously as you have opted for bucket hours and not dedicated hiring.
It's a convenient and efficient way to manage your developer needs on your schedule.
Explore more


 Dedicated/Regular Hiring
Dedicated/Regular HiringIn dedicated hiring, the number of hours are not fixed like the bucket hours but instead, you are reserving the developer exclusively for your project.
- The developer will work only on your project for a set amount of time.
- You can choose to hire the developer for a week or a month, depending on what your project needs.
- This means our developer will focus exclusively on meeting the needs of your project, without any distractions from other commitments.
Whether you need help for a short time or a longer period, our dedicated hiring option ensures your project gets the attention it deserves.
Explore moreOur Databricks Implementation Process
Every project follows a structured, six-stage process that moves you from initial discovery through architecture design, platform build, testing, and into a fully operational lakehouse with measurable outcomes and full transparency at every stage.
Discovery & Assessment
Before recommending any platform configuration or architecture pattern, we thoroughly understand your current data environment, workload types, team capabilities, and business objectives establishing the foundation for every decision that follows.
We document your existing data sources, data pipelines, data storage mechanisms, and analytics workloads. We walk through the data available to you, its locations, processing methods, and the latency and quality requirements of the consumers.
We categorize your workloads as batch ETL, streaming, interactive analytics, machine learning training, and Business Intelligence reporting workloads and prioritize their migration / deployment considering their business significance and technological complexity.
We evaluate your existing cloud environment (Azure, AWS, or GCP) and provide an estimation of the cost of compute in Databricks. We identify the opportunities to optimize the cost by using cluster policies, auto-scaling, spot nodes, and serverless SQL.
We review your engineers' Spark, Python, and SQL competency to assess what training is needed, what level of architecture documentations required, and where Dotsquares Databricks experts should be brought in to boost delivery.
Design
With a clear picture of your environment and requirements, our architects design the lakehouse platform; defining the workspace topology, data organisation strategy, governance model, and pipeline architecture before any infrastructure is provisioned.
We design your Bronze, Silver, and Gold Delta Lake layer structure by defining data partitioning strategies, table formats, incremental processing patterns, and the transformation logic that moves data from raw ingestion to analytics-ready.
We will design the metastore for Unity Catalog, which will include the structure of the catalog and schemas, what can be done by whom (privileges), classifications of the data, and row level security policy.
We design the Workflows DAGs that orchestrate your pipeline by defining task dependencies, trigger types, cluster configurations, retry policies, and alerting rules for every workflow in scope.
The complete architecture including workspace topology, network design, compute configurations, governance model, and pipeline flows is reviewed and approved by your engineering and data leadership before any implementation begins.
Development
Our platform and pipeline are built incrementally. We first create our infrastructure and then build our pipelines iteratively to provide you with insights into your lakehouse early, even before the entire process is completed.
We provision workspaces using Terraform or Azure Resource Manager, configure VNet injection or Private Link for secure connectivity, and set up the identity federation with your cloud IAM service.
We build your data transformation pipelines using Delta Live Tables writing declarative transformation logic, configuring data quality expectations, and setting up streaming or triggered execution modes as appropriate for each pipeline.
We configure Lakeflow connectors and Autoloader for managed data ingestion, handling schema inference, schema drift, and incremental load patterns for every data source in scope.
Where your operational workflows require programmatic Databricks control, we build the API integrations, CLI automation scripts, and Terraform modules that embed Databricks into your broader platform engineering ecosystem.
Testing
Before any production data flows through your lakehouse, we run a comprehensive validation programme covering data quality, pipeline performance, compute costs, and governance control effectiveness.
We validate every Delta Live Tables pipeline against defined acceptance criteria testing row counts, schema conformance, data quality expectations, and business rule logic using representative data volumes.
We benchmark query performance on SQL warehouses, optimize Delta Lake table layouts using Z-ordering and compaction, tune cluster configurations for job workloads, and validate that compute costs align with budget targets.
We execute full end-to-end workflow runs validating task dependencies, retry behaviour, alerting triggers, and SLA compliance under realistic scheduling and load conditions.
We systematically test every access control policy verifying that users can access exactly the data they are entitled to and nothing more, including row-level security, column masking, and cross-workspace sharing scenarios.
Deployment
Moving your production workloads onto required precise coordination. We manage the full production deployment from infrastructure finalisation and historical data migration to operational cutover and post-go-live monitoring.
We migrate historical data from your legacy systems data warehouses, flat files, on-premise databases, or other cloud storage into Delta Lake format, with full validation of record counts, data types, and business rule conformance.
We activate production Workflows confirming trigger configurations, dependency chains, and alert routing and run the first production pipeline cycles under close monitoring before declaring go-live.
We validate that Power BI, Tableau, Looker, or Dashboard connections are functioning correctly against production SQL warehouses, and confirm that report outputs match expectations before business users access the new platform.
For two to four weeks post-go-live, our team provides dedicated hypercare support monitoring job runs, cluster health, SQL warehouse performance, and Unity Catalog audit logs resolving any issues before they impact downstream consumers.
Support
It is a living platform, it must evolve as your data volumes grow, new workloads emerge, new platform capabilities are released, and your team's data ambitions mature. We provide the ongoing engineering support to keep your platform performing, cost-efficient, and ahead of the curve.
We monitor job performance, SQL warehouse utilisation, compute costs, and Delta Lake storage growth continuously identifying optimisation opportunities before they become performance issues or budget overruns.
As It releases new capabilities Databricks Lakeflow enhancements, Serverless compute, AI/BI dashboards, or MLflow improvements we evaluate and implement the ones that deliver the highest value for your specific use cases.
When source systems change, new data sources are added, or business logic evolves, we update Delta Live Tables pipelines, Workflows configurations, and Unity Catalog policies to keep your platform aligned with current requirements.
As your internal team grows into the platform, we support capability building, delivering targeted training, pairing our engineers with your team on new features, and helping you establish a Centre of Excellence.
Still not sure what you are looking for?
Talk to Our Experts
Built Relationships with 15,000+ Happy Clients!
Companies employ software developers from us because we have a proven track record of delivering high-quality projects on time.

5+ Years of Average Experience

Integrity & Transparency

FREE No Obligation Quote

ISO 27001 Information Security

Outcome-Focused Approach
Transparency is Guaranteed

Focus on Security

4.8/5 Rating on Clutch
Hire a Team of Your Choice

Costs Lower Than Your Local Guy

Leading Technology Partners and Achievements
With a history of excellence and innovation, we've been honored with several significant awards and partnered with leading technologies.




























Frequently Asked Questions
Find answers to common questions about our services, process, and expertise.
It is a unified platform combining data engineering, warehousing, streaming, ML, and AI on a single Delta Lake foundation, replacing the need for separate tools across each workload.
